Self Organizing, Production Maintenance, and Mob Programming Q&A; Target software team
Markus S forwarded questions from his team at Target:
The teams using PCs are currently
using the mob timer made in Python that we maintain:
Here is a video:
The team using Mac is using Dillon
Kearns timer: Here it is on GitHub
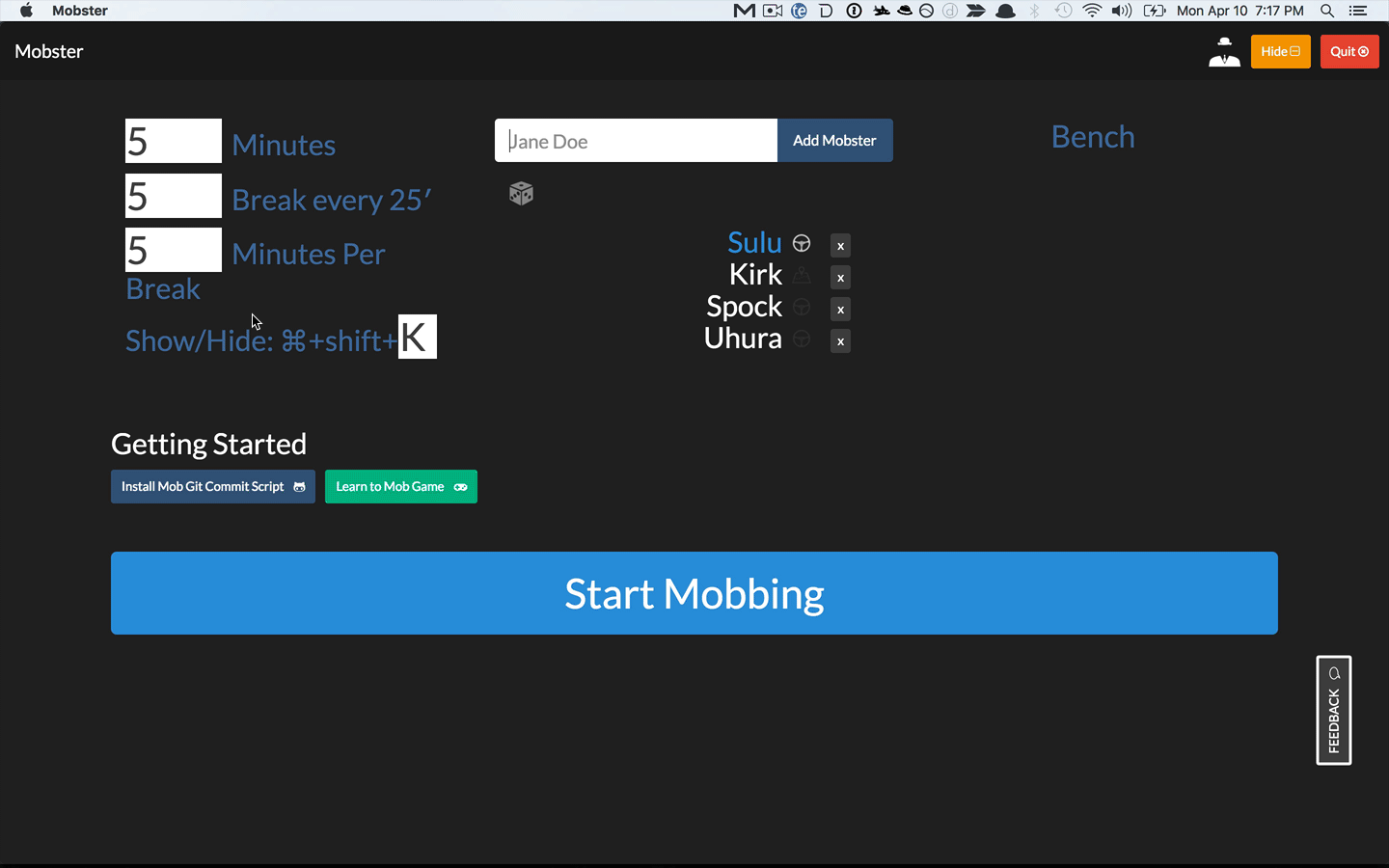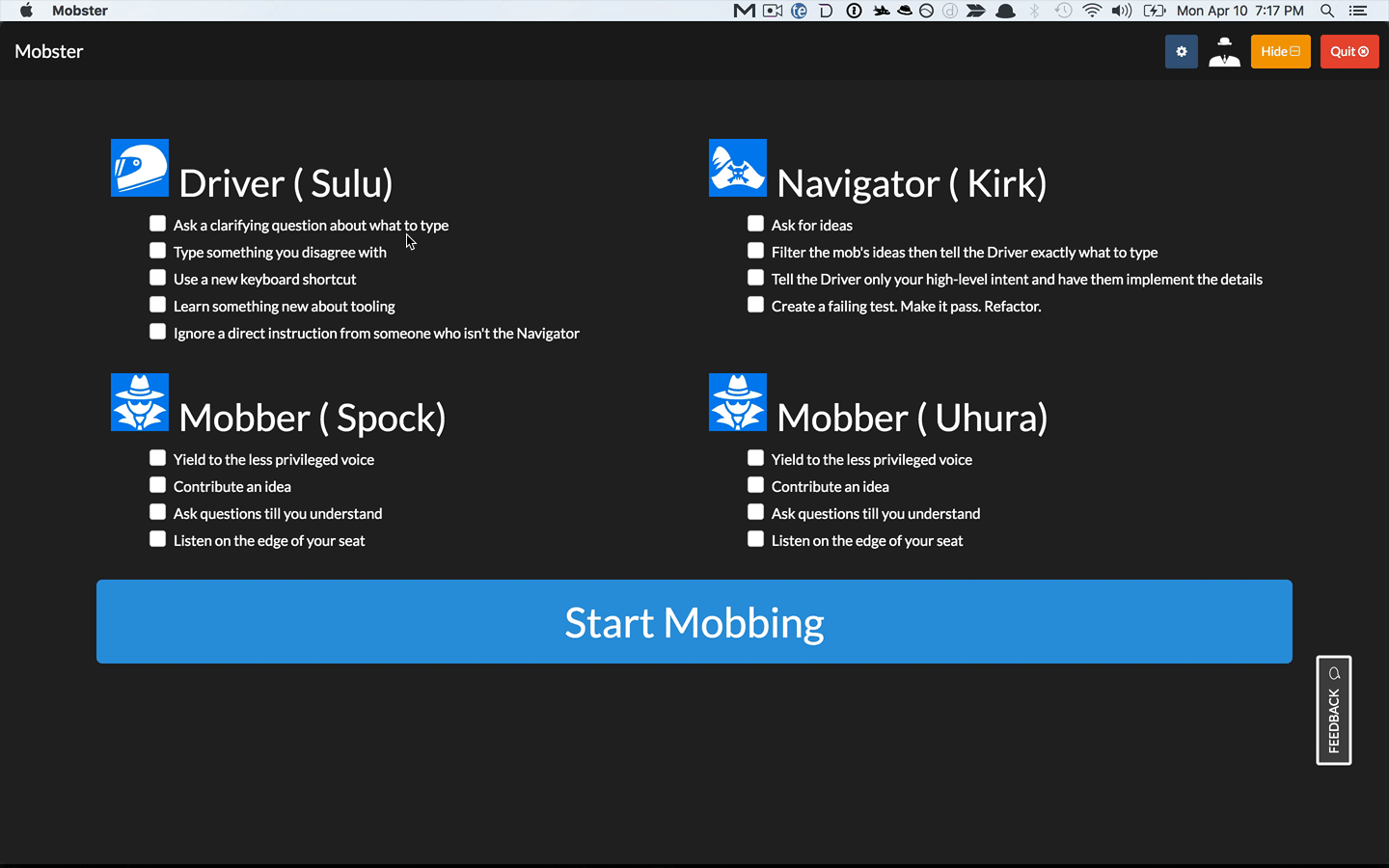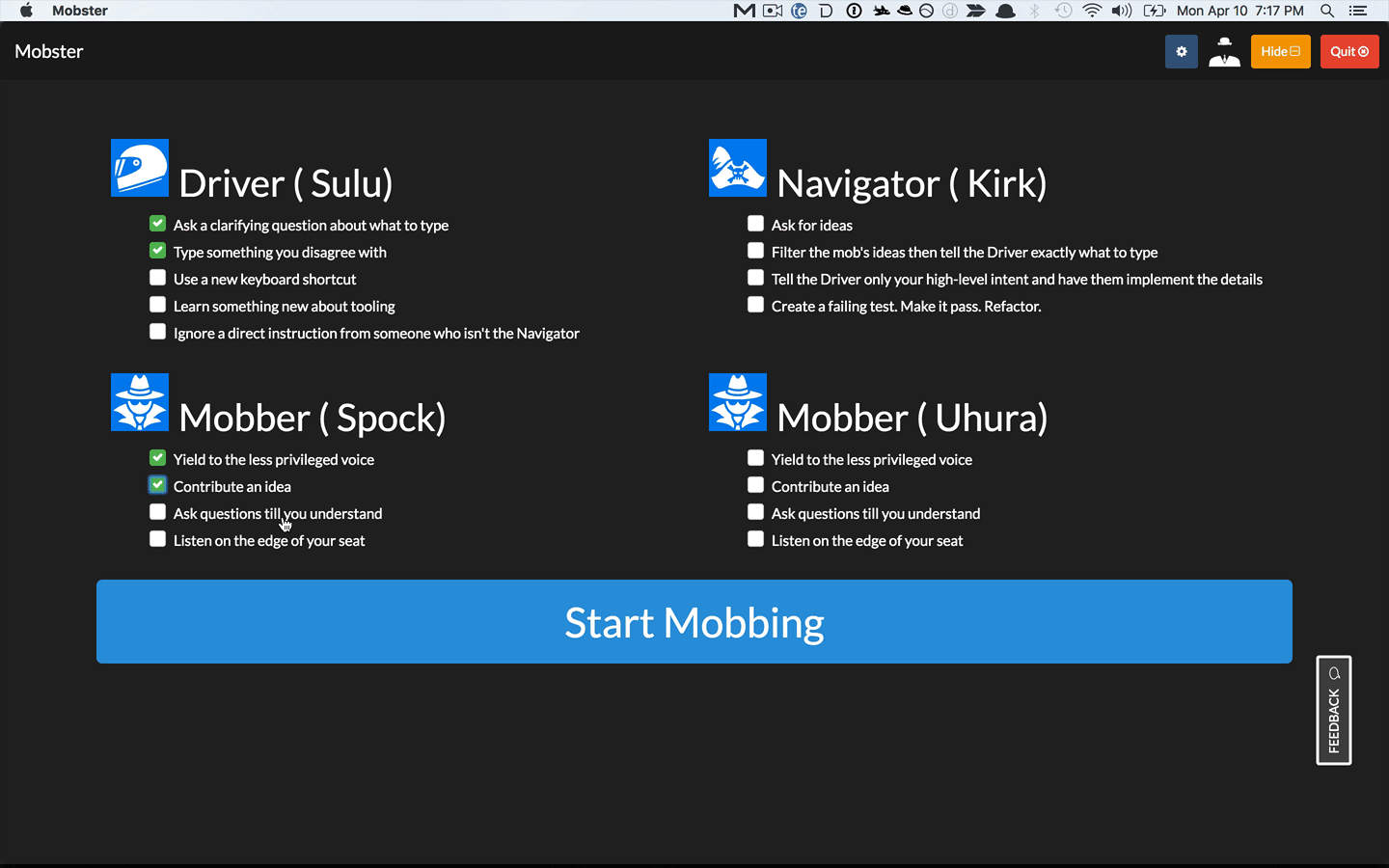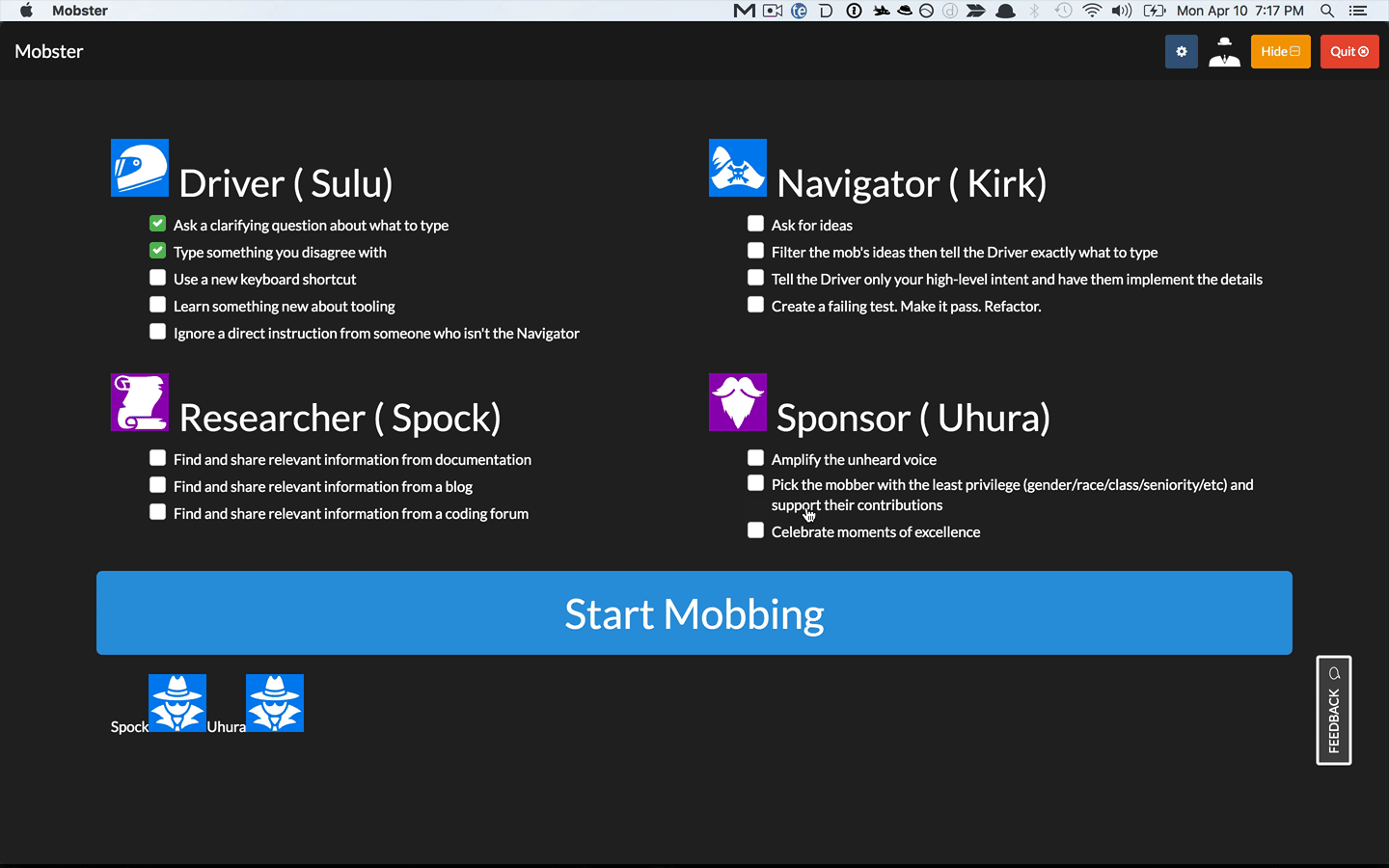
You mentioned that mobs switch roles every 5-15 min. How do mobs choose a rotation length? Does it vary based on the mob, the type of work, or other factors?
The teams do regular retrospectives.
Either daily 30 minutes and the end of each day or once a week on Friday or Monday.
Rotation length comes up in these retrospectives. Sometimes the rotation length
adjustment becomes an action item of the retro. A rule of thumb we use is to
decrease rotation length if people are having trouble paying attention since
you have to engage to prevent the team from slowing down with the rotation. I
have seen timers set to 2 minutes and 30 seconds. I have also seen timers set
to 30 minutes. We say 5 to 15 usually because that is where the majority of
teams reside. I personally think 5 or 7 minutes are good times.
At Agile2017, Jason K mentioned an external audit that recommended an expansion of mobbing across more teams. Was that a specific type of standard audit? What type?
At the time there was an external consultant, Craig Shohara that compared the processes of each team. He was not tasked with changing any teams process only to evaluate which direction was better. He compared the teams processes and he reported back the difference in results and the recommendation as his findings. The audit was not standard, instead it was an analysis and comparison by a qualified third party that was not partial to either of the teams. Based upon his findings that the Mob team’s practices result in higher quality software developed in less time while delivering greater business value, the organization made a decision to expand the Mob team and transition critical software development projects to the Mob.
What sort of ops environment(s) do the mobs deploy to? Do the mobs also do production support for their apps?
To explain this it is useful to show
our Lofty Goals:

Ideally, we have zero people between
code and production (everything automated). We use Go.CD to do our continuous integration
and delivery. Most project teams (one or more mobs) will handle their own
DevOps up to the production environment, then we collaborate with out network
services team to get automated production deployments together in an
environment where we have little to no access.

We do have one project team composed
of 3 mobs that has its own DevOps mob. This mon essentially focuses its entire
day on deployment automation and monitoring.
As far as the deployment environment
goes we have multiple solutions the team is developing. We have a desktop
application used in the Golf industry, a worldwide scale IOT application in AWS
composed of web servers, microservices and lambdas, a mobile application that
controls lighting systems cross platform in Xamarin, and we have internal IT
applications that are either desktop or internal web server. All of these
systems are getting deployments from GO.

Finally, for production support that
ends up in our hands we have the above process. Automate before fixing, fix,
then automate after fixing. i.e. the bug should never return. Over time we have
reduced hours spent on production issues to 0 with brief spikes of time. The
idea is never let the issue return to the team if automation can handle it. The
ticket team is composed of Mobbers from each team that assemble based on a
weekly rotation. Since we value Zero Silos we desire that the loss of a team
member to the Ticket team will have little to no effect on the teams progress.
Chris L mentioned a period of 18 months with zero known bugs in production. Prior to that, what were the production bugs rates like? How confident are you that there weren’t a bunch of bugs that just went unnoticed?

Bug rates before were typical of
every other environment I had before about 300 bugs in a bug tracker that a
manager was not willing to prioritize and many more unknown bugs. If you
reference our Lofty Goals above we mention ZarroBoogs (Zero known bugs). We could have had something but we never found anything. Our
bug rates increased as we began scaling because of the natural disruptions
caused by hiring however even with 8 mobs we still do not keep a bug tracking
software.

If there is a bug in production / on master we stop everything until all bogs are out of the code. We unit test and automated acceptance test the bug before moving on so we do not get PingPong bugs (bugs that 2 developers keep fixing not know they are causing the other’s bug) As of today there are no known bugs in our production environments, some mobs go months without bugs and worst case is about a bug reported once a week which has been moving in the better direction.

If there is a bug in production / on master we stop everything until all bogs are out of the code. We unit test and automated acceptance test the bug before moving on so we do not get PingPong bugs (bugs that 2 developers keep fixing not know they are causing the other’s bug) As of today there are no known bugs in our production environments, some mobs go months without bugs and worst case is about a bug reported once a week which has been moving in the better direction.
I know it sounds hard to believe but
when you implement “Stop the Line” from Toyota’s lean manufacturing to your
code life becomes much safer.
Have you found an “upper limit” to the useful size of your mobs? Size of the mob. I feel that above 4 it gets to hard. - Brian
We have a heuristic: “If you are not
learning or contributing, go to a different mob”
With that said I do not limit the
size of the mobs but the business budgets for a set number of people on a
project. i.e. if a project has budget for 9 people. The team can decide to do a
Mob of 5 and 4, or 3 mobs of 3, or 4, 3, 2 etc.. We try to only go down to a
pair when the work is simple and not easily automatable.
I have been in a 20 person mob at a
Open Space that was about a technology and language no one knew. Everyone in
the room was engaged and contributing as different threads of research were
bubbled up to the navigator. Obviously not sustainable but a great example of
why you might go so large. We typically normalize at 4 however we have
experienced lack of slack at 4 and some think having 5 might be better for unplanned
absences like bathroom breaks etc..
A Great experiment would be to have
someone dedicated to each role in Willems Mob programming game and see what the
engagement level is.


Did you have fun? (j/k) But seriously, did you have fun?
If you’re asking about mobbing
specifically, I think mobbing is both fun and can be stressful at times. We mob
full time so the people here need to like it however we have notices 2 trends
when on boarding. Some people like it right away and others hate it for about 3
months then begin to like it.
I regularly do happiness
retrospectives where I meet with every member of the team and get a 6 month
timeline of their experience. Overall a majority of the team is very happy with
the way we work.

Do you do any sort of self selection? (In our group at Target, we reshuffle our teams quarterly using a self-selection process very similar to what’s described in Sandy and David’s book and workshop. People are curious whether Hunter teams do anything similar, and how that affects mob effectiveness.)
I love to hear about other teams
doing this! We have a “law off personal mobility” policy here. This means that
team movement is purely negotiation based. You can move on to another team at
any time, either there is a vacant budgeted headcount (i.e. while we are
hiring) or you can negotiate with someone on another team to switch positions.
Finally anyone can join another team
as a visitor for up to 2 weeks violating budgeted headcount in order to learn
about how another project team solves
problems.
We broadcast this information on a
sheet of flipchart paper and stickies containing each person’s name.

How do Hunter mobs keep focus when there are interrupts, such as production incidents, drive-by requests for help from other internal groups/people, etc?
We try and avoid production incidents,
at this point we have so few that the interruption is minimal. A teams priority
is done by pure Kanban and we don’t interrupt the team when completing a card.
We use magnetic whiteboards with 3x5 index cards to track all work, we keep it
out of a digital system so deleting is easier (Physical Trash Can). (This is a
great habit that Woody put in place 5 years ago) Anything that gets
re-prioritized goes into the Kanban, we deploy every feature as a vertical
slice (A single mob has done 2 prod deployments per day for an extended time)
This means that drive by requests become a new priority on the board and the
team finishes their current deployment and digs into the next task.
I will say if it is management related
drive by requests, the mobs are very resilient to these since we value Zero
Silos. Ideally a mob can keep moving if you pull away one of the 4 people
working with little to no disruption. One of the best analogies I have heard
was “Mob programming is like a steam roller, it does not feel fast but high-quality
code just keeps flowing out no matter what happens”
Are all your passwords ‘Hunter2’?
Yes… now we have to change it ☹
We are currently transitioning from
our old way of doing it (not described here) to using randomized complex
passwords that regularly change. These passwords are then pulled to the mob by
the current driver logging in making them responsible for the use of the
password at the time.
Another note here is that the driver
types in their username and password (also regularly changing) for each push in
order to maintain a chain of responsibility isolated to one person. The rule is
that you must understand and agree to be legally responsible for the code you
are checking in.
How do you deal with remote workers during a mob session?
MAKE SURE THE MOB CAN SEE THEM! Also
put the camera above their image so you have to turn your head and look at them
to signal you are talking to them.
We have the floating head on wheels:


Software we use is Teamviewer for control
sharing. I have also tried Zoom.US
Skype for Business for video.
Does each mob run a shared machine, or does one member contribute her machine to the mob?
Typically, we use a single machine for a single mob but this
is not the only situation we have seen.
We have 2 keyboards and 2 mice connected to the same
computer based on ergonomics preference.

We have also experimented with a mob of 5 doing 3 and 2 on
two different machines and 2 different projects. They rotated 1-person daily
and had great success with it. So, you worked on one project 3 days then the
other 2 days. They had great success with this when supporting 2 high priority
internal IT projects.
We have also done dojos where we work on the same problem in
multiple languages and rotated drive navigator on each machine. We use this technique
for practicing TDD and learning new languages. We have not tried this format
for production work however. Might be an experiment one day.











Hi Chris, it would be very interesting if you could write a blog post about your DevOps mob.
ReplyDeleteIt would be very interesting to see how they are organised, how they work, how they articulate their work with the other teams, what is their role and what is left to the other teams, do they work in mob programming, are they in charge of end-to-end tests, and performance tests,and so on !
THat would be very nice from you to share on that topic !
As soon as I get some time I will try write something up!
DeleteHey Nicolas, It looks like I never got around to writing this post, I saw this comment again and wanted to elaborate a bit. Right now most mobbers do their own devops. There is one person in the department with a title of DevOps engineer but this person just goes from mob to mob to work on either development or devops. The only difference in the title is their use of their learning time. A software engineer learns about software engineering, a devops engineer learns more about devops engineering. Everyone works on the next most important thing!
DeleteThank you, Hunter/mobbers/Chris.
ReplyDeleteIMO when the final chapter in human-written code is written, mobbing will be recognized as one of the radical practices that made it possible.
One question... It seems like your process map needs one more box: causal analysis.
BTW nice touch - including Woody in the team photo.
Hey Ian,
DeleteThanks for the great compliment! I agree with you the causal analysis should go on the diagram, thanks for the feedback!